这两天面试了一些前端同行,面试别人同样是宝贵的经验,因为在问别人的同时,自己也会思考,这题的答案是什么,除了这种解法还有没有其他解法呢?所以这篇博文,我把自己问的问题作一个归纳与总结,并分为三个层次,基础,提升,高级,并且写一些比较冷门的前端知识。
Vue
基础篇
vue-rouer有几种模式,区别是什么?
两种模式,hash模式与history模式 ,
vue-router默认使用hash模式,hash模式的url格式一般为http://.../#/...,history模式则没有/#/,并且history模式需要后端配合,因为vue一般写的是单页面应用,如果后端没有正确的配置,用户直接访问http://oursite.com/user/id则回提示404错误。
vue-router路由传参有几种方法?
通过
params或query传参,前者参数不在url上显示,刷新页面会丢失参数,后者会在url上显示,刷新页面不会丢失参数。
路由的动态传参,这种方式首先要在router.js中配置路由对应的path为{ path: '/user/:id', component: User }这种格式,在对应得页面可以通过this.$route.params来获取对应的参数。
vue-router的导航守卫有哪些?
前置守卫:
router.beforeEach(常用)当一个导航触发时,全局前置守卫按照创建顺序调用
解析守卫:router.beforeResolve(不常用)与前置守卫相识,区别在于导航被确认之前,同时在所有组件内守卫和异步路由组件被解析之后,解析守卫就被调用。
后置守卫:router.afterEach(不常用)不会接受 next 函数也不会改变导航本身:
独享守卫:beforeEnter(不常用)在路由配置里定义,用来对单独的路由作处理
守卫一般有三个参数
to:Route:即将要进入的目标 路由对象from: Route:当前导航正要离开的路由next: Function:必须调用的跳转方法,否则不会进行路由跳转
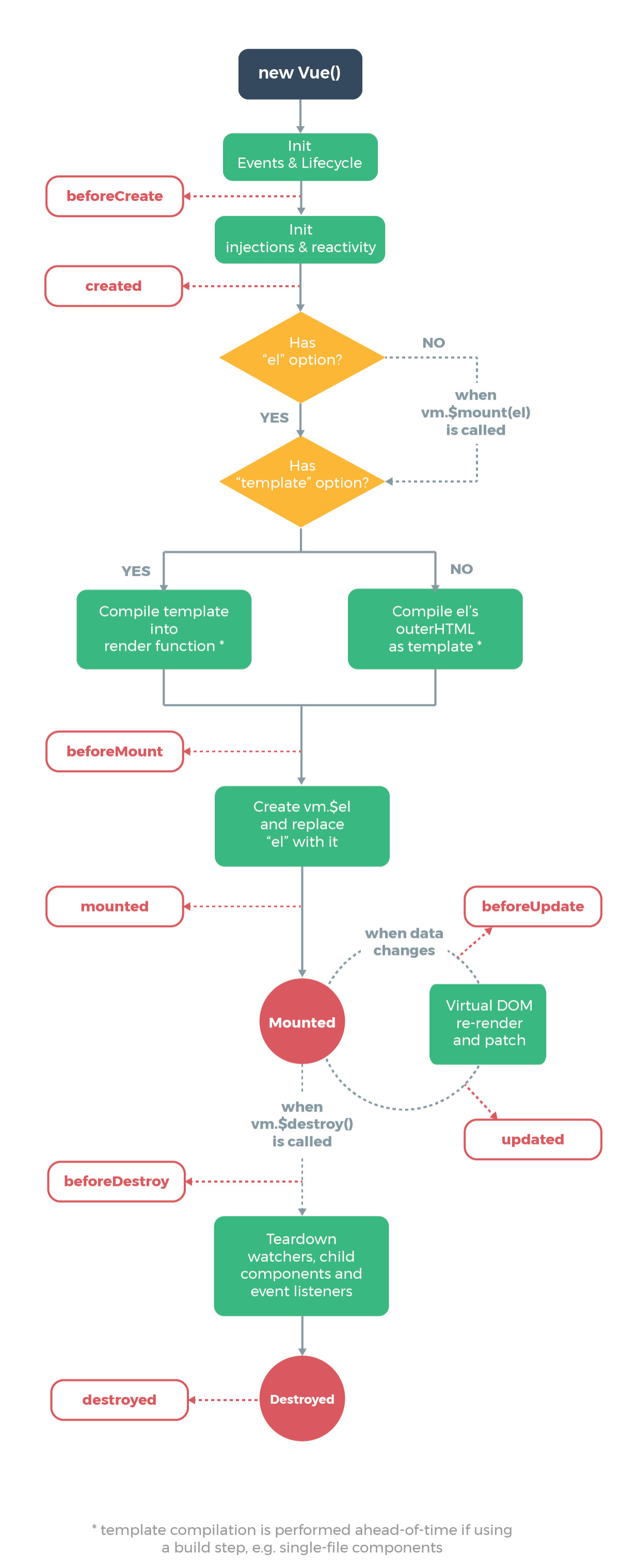
简单介绍一下vue 的生命周期函数?
beforeCreate: 初始化之前的函数,vue实例不可访问,data未定义,一个基本不怎么用的函数
created: 初始化函数,data已被定义,可以访问data里的数据,可以进行绑定,判断是否有el选项,有则继续进行,没有则停止编译(生命周期停止),直到在该vue实例上调用vm.$mount(el)。接着判断是否有template选项,如果有,则会将template作为模板编译成render函数,如果没有,则将外部HTML作为模板编译。如果同时存在,template模版优先级是高于外部HTML的。同时vue对象中还有一个render函数,以createElement作为参数,然后做渲染操作,而且我们可以直接嵌入JSX,这个优先级是最高的。综上所述,模版优先级:render函数>template模版>外部HTML。
beforeMount: 给vue添加$el成员,并且替换挂载的DOM元素。建立虚拟dom,data还是以参数名的方式挂载在节点中,没有注入数据。
mounted: 第一次对组件进行渲染,将data里的数据注入节点中,这时已经形成了真实dom。这个函数vue的整个生命周期中只会执行一次,如果还有数据的变化,只会触发updated相关函数。
beforeUpdate: 检测到data发生变化,准备对相应的组件再次渲染。首先重新渲染虚拟dom,再对真实的dom打补丁。
updated: 完成对data发生变化的对应组件渲染
beforeDestory: 实例销毁之前调用。在这一步,实例仍然完全可用。
destoryed: 在Vue 实例销毁后调用。调用后,Vue 实例指示的所有东西都会解绑定,所有的事件监听器会被移除,所有的子实例也会被销毁。
帖一张官方的生命周期图
vuex的核心概念包括哪些内容。内容比较多,详情看vuex官网
state:存放状态数据的字段,辅助函数mapStategetter:可以认为是 store 的计算属性,辅助函数mapGettermutation:更改store状态的唯一方法,必须是同步操作,辅助函数mapMutationaction:action类似于mutation,不过无法直接变更状态,需要通过提交mutation来更改,可以包含任意的异步操作,辅助函数mapActionmodule:store的模块,每个模块拥有自己的state、mutation、action、getter、甚至是嵌套子模块。通过设置namespaced: true的方式使其成为带命名空间的模块,如果需要在带命名空间的模块访问全局内容,rootState和rootGetter会作为第三和第四参数传入 getter,若需要在全局命名空间内分发action或提交mutation,将{ root: true }作为第三参数传给dispatch或commit即可。
JS
基础篇
说一些与Array相关的api,并且挑几个详细说明它们的作用?
concat: 合并两个或多个数组,不会改变原数组,返回一个新数组every: 测试数组所有元素是否通过制定函数的测试some: 测试数组是否存在元素是否通过制定函数的测试forEach: 对数组的每个元素执行一次提供的函数。reduce:对数组中的每个元素执行一个由您提供的reducer函数(升序执行),将其结果汇总为单个返回值。第一个参数为执行函数,第二个参数为执行函数第一次调用时它第一个参数的值map: 创建一个新数组,结果为该数组每个元素调用函数的结果filter: 过滤,创建一个新数组, 其包含通过所提供函数实现的测试的所有元素。entries: 返回一个新的Array Iterator对象,该对象包含数组中每个索引的键/值对。find: 返回数组中满足提供的测试函数第一个元素的值findIndex: 返回数组中满足提供的测试函数第一个元素的索引,没有返回-1flat: 按照一个可指定的深度递归遍历数组,并将所有元素与遍历到的子数组中的元素合并为一个新数组返回。(IE不支持该方法)includes: 判断一个数组是否包含一个指定的值concat: 合并两个或多个数组,不会改变原数组,返回一个新数组join: 将一个数组(或一个类数组对象)的所有元素连接成一个字符串并返回这个字符串。如果数组只有一个项目,那么将返回该项目而不使用分隔符。splice: 通过删除或替换现有元素来修改数组,并以数组形式返回被修改的内容。此方法会改变原数组。三个参数,start(指定下标),deleteCount(移除的个数),[item1,item2,…]从start位置开始插入的元素。slice: 返回一个新的数组对象,这一对象是一个由 begin和 end(不包括end)决定的原数组的浅拷贝。原始数组不会被改变。reverse: 倒序sort: 排序push,pop,shift,unshift数组堆栈操作
js的基础类型有哪些?
String,Boolean,Number,Object,Undefined,Null,Symbol
var,let,const三种声明变量的方式有什么区别?
var声明变量有变量提升的功能 能重复声明let声明一个具有块级作用域的变量,不具备变量提升功能,重复声明会报错const声明一个具有块级作用域的常量,并且常用大写字母作为变量名,不具备变量提升功能,重复声明会报错,重新赋值也会报错
提升篇
Object.assign()方法只会拷贝源对象自身并且可枚举的属性到目标对象,那么如何拷贝不可枚举的属性和继承属性呢?
首先说一下如何拷贝不可枚举的属性。
何为不可枚举属性,其实对象里每一个键值对都有6个配置选项。比如obj = {a:1}这样的数据结构,他是与
1 | Object.defineProperty(obj,'a',{ |
当设置了属性的enumerable为false时,这条属性就是不可枚举属性,即无法通过for..in..与Object.keys()获取到
首先你得通过Object.getOwnPropertyNames(obj)(能获取到不可枚举的属性的键名,但是获取不到以Symbol作为键名的属性)或者Reflect.ownKeys(obj)(获取到所有属性的键名)的方法获取到包括不可枚举属性的一个数组。
然后循环这个数组,通过Object.getOwnPropertyDescriptor(obj,propkey)的方法得知每一个属性的描述符,然后筛选出enumerable:false的属性,重新通过Object.definePropertires(newObj,{'propkey1':{...},'propkey2':{...}})的方式放入新的obj里,其他可枚举的属性通过Object.assign({},obj1,...,objn)的方式放入就好了。
至于继承属性的问题,可以通过Object.getPrototypeOf(obj)的方式获取指定对象的原型,然后设置新数组的__proto__为这个原型。问题就解决了。
当然有一种更好的方法。
配合使用Object.create()可用达到同样的目的
1 | let newObj = Object.create(Object.getPrototypeOf(obj),Object.getOwnPropertyDescriptors(obj)) |
CSS
基础篇
display:none与visibility:hidden与opacity:0(兼容写法filter:alpha(opacity=0))的区别?
他们都能让元素消失不见。
display:none会让元素从渲染树中消失,渲染时不占任何空间,从而达到消失的目的。visibility:hidden与opacity:0只是让元素不可见,元素不会从渲染树消失不见,继续占据空间。display:none是非继承属性,元素直接消失了,修改子孙节点属性无法显示。visibility:hidden是继承属性,通过修改子孙属性visibility:visible可以让子孙节点显示。opacity:0,消失的原理是将元素的透明度设置为0,是继承属性,子孙节点通过设置opacity:1无法显示,可以继续触发元素上绑定的事件。
修改元素的display通常会造成文档的回流,修改visibility与opacity属性只会造成本元素的重绘。
技巧
基础篇
对手机号做加密处理,将中间四位数字用*代替
replace方法1
phone.replace(/(?<=.{3}).(?=.{4})/g,'*')
substring方法,或substr方法1
2
3phone.substring(0,3)+'****'+phone.substring(6,4)
//or
phone.substr(0,3)+'****'+phone.substr(-4)数组
splice方法1
arr=phone.split();arr.splice(3,4,'****');arr.join('')
处理金钱字符串,例如‘1234567’=>’1,234,567’
正则法
1
str.replace(/\B(?=(\d{3})+(?!\d))/g,',')
js法
1
2
3
4
5function formarMoney(str){
return str.split('').reverse().reduce((pre,next,index)=>{
return ((index%3) ? next : (next+',')) + pre
})
}toLocaleString 法(这个是真的牛皮)
1
(23333333).toLocaleString('en-US')
介绍一下ES模块语法
使用
export关键字导出一个变量或者类型1
2
3
4
5
6
7
8
9
10
11export const someVar = 1;
export type someType = {
foo:string
}
export interface someInterface = {
foo ?:string
}
// 在提前定义好变量或者类型后,可以这样导出
export {someVar,someType}
// 重命名变量导出
export {someVar as aDifferentName}使用
import关键字导入一个变量或者一个类型1
2
3
4
5
6
7
8
9
10
11import {someVar,someType} from './foo'
// 重命名导入变量或者类型
import { someVar as aDifferentName } from './foo';
// 使用整体加载
import * as foo from './foo'; // 你可以这样使用foo.someVar了
// 仅导入模块
import 'core-js'; //工具库
// 从其他模块导入后整体导出:
export * from './foo';
// 从其他模块导入后,部分导出
export { someVar } from './foo';使用默认导入/导出
export default使用
export defalut与export的区别:- 导入使用时可以根据需要自定义导入命名,比如这样的语法
import someName from 'someModule' - 导出变量,函数,类不需要提前定义,比如
1
2
3export default (someVar = 123);
export default function someFunction() {}
export default class someClass {}
- 导入使用时可以根据需要自定义导入命名,比如这样的语法
重写类型的动态查找
在项目里可以通过
declare module 'somePath'来声明一个全局模块的方式,用来解决查找模块路径的问题
全局类型声明写法1
2
3
4
5
6
7
8
9// 全局类型声明写法
// **暴露**
declare module 'foo' {
// some variable declarations
export var bar: number;
}
// **引入**
import * as foo from 'foo';模块导出声明写法
1
2
3
4
5
6
7
8
9// 模块导出声明写法
declare interface funcAbcSign {
(s: string): string
}
export declare let abc: funcAbcSign;
export declare function fn();
// 引入
import {funcAbcSign,abc} from 'foo';全局类型声明里的名称将被引入整个 TypeScript 全局命名空间中,从引用这个 声明文件起就可以自由使用。
模块导出声明里的名称必须通过 import/require 才能使用。
提升篇
介绍一下你了解的排序方式
冒泡排序
冒泡排序是一种非常简单的排序方式,这个算法的名字由来是因为越小的元素会经由交换慢慢“浮”到数列的顶端。
排序基本思想为循环序列内每一个元素,循环到的元素与相邻的元素作对比,每次循环会将最小或者最大值冒泡至最底部,直到整个循环结束。
1 | for(let i=0,l=arr.length;i<l;i++){ |
改进冒泡排序: 设置一标志性变量pos,用于记录每趟排序中最后一次进行交换的位置。由于pos位置之后的记录均已交换到位,故在进行下一趟排序时只要扫描到pos位置即可。
改进后如下
1 | let i = arr.length-1; |
选择排序
选择排序是一种简单直观的排序算法,它的原理是:首先在未排序序列中找到最小(大)元素,存放到排序序列的起始位置,然后,再从剩余未排序元素中继续寻找最小(大)元素,然后放到已排序序列的末尾。以此类推,直到所有元素均排序完毕。
1 | let tmp,minIndex; |
插入排序
插入排序的远离应该是最容易理解的了,就像打扑克牌,摸到牌以后,你需要对牌进行从小到大的排序,如果你打扑克从不排序,那当我没说…
它的工作原理是,构造一个有序序列,然后拿未排序的数据在已排序序列中从后向前扫描,找到相应位置插入。
1 | for(let i=1,l=arr.length;i<l;i++){ |
未完待续…

